Identifying Query Traps
A Query Trap refers to a construct in a data model that can generate undesired query results. This can confuse end users or even give incorrect results.
Loop Trap
Loops refer to the multiple possible paths from entity A to B in a data model. Loops can exist in different forms: a self join or multiple join path. The Data Modeler in InetSoft's business intelligence software automatically highlights these loops in red.


An employee table containing a “manager id” column that points to itself to indicate an employee’s manager is a self join loop. This self join must be resolved to allow end users to find employees and their respective managers.
Self join loops are most easily resolved by creating a table alias.

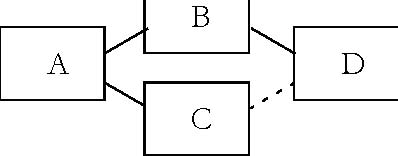
The multiple table loop has the potential to create results that are too restrictive. An order table (A) joins to the “ship to” table (B) and the “bill to” table (C), which in turn joins to a “company” table (D). If end users select data from all four tables, only orders that have the same company for “bill to” and “ship to” will be returned.
Multi-table loops can be addressed using aliasing or auto-aliasing. Additionally, these loops can be addressed using a weak join which will not be included in the join path of the resultant query.
In creating a physical view, you should identify and address all possible query traps so that the end user cannot produce confusing or incorrect queries. A subject-based physical view design will minimize query traps. This design approach also segments a complex schema into manageable, easy-to-understand subsets.

Higher Level Aggregate Trap
A measure is a numeric value that can be aggregated. Aggregation of fields at a lower level is always correct, but incorrect results can be produced when a higher level field is aggregated.
When an order table that contains total order amounts is joined with an order items table, aggregation by order item will recount the order total multiple times if an order contains more than one order item.
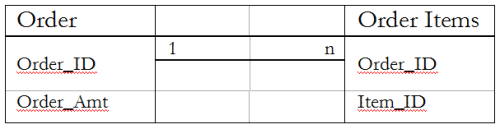
This trap can be readily identified by relationship cardinality. If the specified measure is in a table that has a 1-n relationship with another table, and the measure exists in the “1” side table, this error will occur.
This trap is a display of an inherent deficiency in the particular schema. The schema is not providing the order amount on the item granularity level. If this aggregation is desired, the best option is to enhance the schema so that the order amount data is broken down and recorded in the order item table.
If this aggregation is not desired, two physical views should separate the measure and the lower granularity table to prevent incorrect aggregation. A data view that shows both order price and all associated items can still be assembled in the InetSoft Data Block. environment by creating a data worksheet.

Higher Level Join Trap
This trap relates information incorrectly because the association is established at too high a level.
A customer table is related to a product table to record products ordered by a customer. The same customer table is also related to a support case table that records the product issues the customer reported.

This physical view will lead end users to believe that it is possible to view issues by product. However, because the product table and issue table are linked through a higher level table, “customer”, this is not possible. Through these joins, each product a customer purchased will be associated with all issues this customer raised regardless of the product.
This trap is readily identifiable by the combination of n:1 and 1:n. If “issue by product” data is desirable, the issue table must be enhanced with a direct relationship to the product table. The resulting loop could be resolved using a weak join. Otherwise, these two relationships should be isolated in two physical views. InetSoft Data Block technology can be used to assemble these two views together.
In order to deliver an easy-to-use data model, identifying and addressing query traps in the physical view is essential. These traps most likely will not exist in a star schema because that schema has uniform 1:n relationships from dimension table to fact table and all measures are located in the fact table.
