Data pipeline for
more than data preparation
Transform, combine, and script data using a pipeline. This fully accessible pipeline allows you to review each step, create data quality assurance test cases through visualization, and attach monitoring.

Connect data
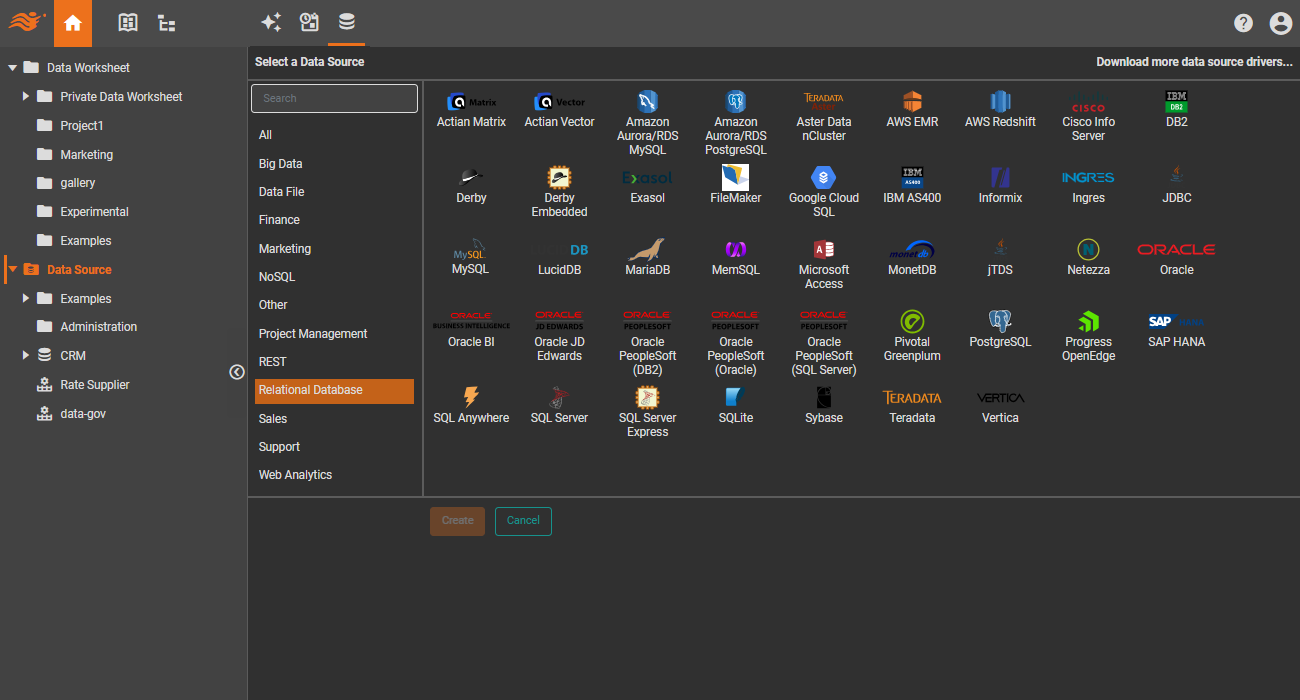
A comprehensive library of data sources, open-sourced for you to create your own
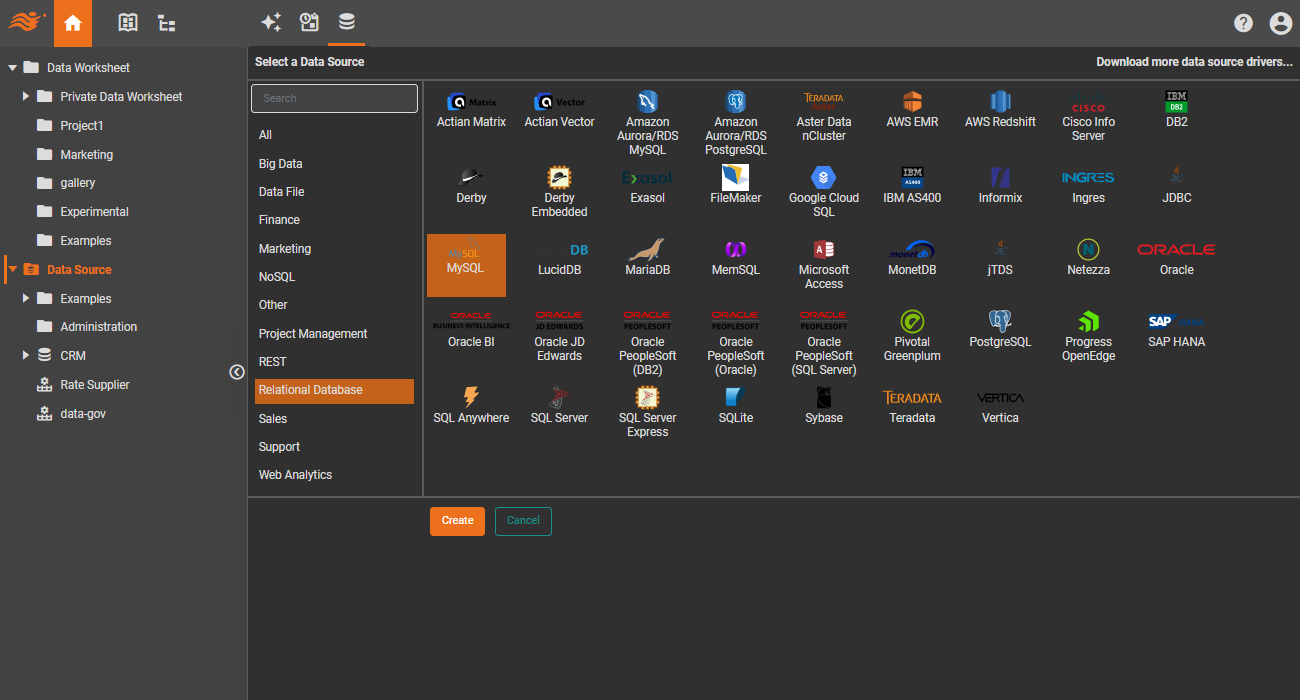
Self-hosted databases
Built-in connectors for a wide range of SQL, NoSQL databases and data warehouses, whether in a public or private cloud. Any database with a JDBC driver can be easily integrated.
Cloud big data stores
Directly support large cloud data stores, including RedShift, Snowflake, BigQuery and Databricks.
SaaS app data sources
Many cloud data sources, such as Facebook and Twitter, are accessible through APIs. Most SaaS applications also typically provide API access. The most widely used data sources are already integrated into StyleBI.
Generic REST API
A generic REST API data source is available, which can be customized to access any REST API. This offers a more straightforward alternative to creating a new data source.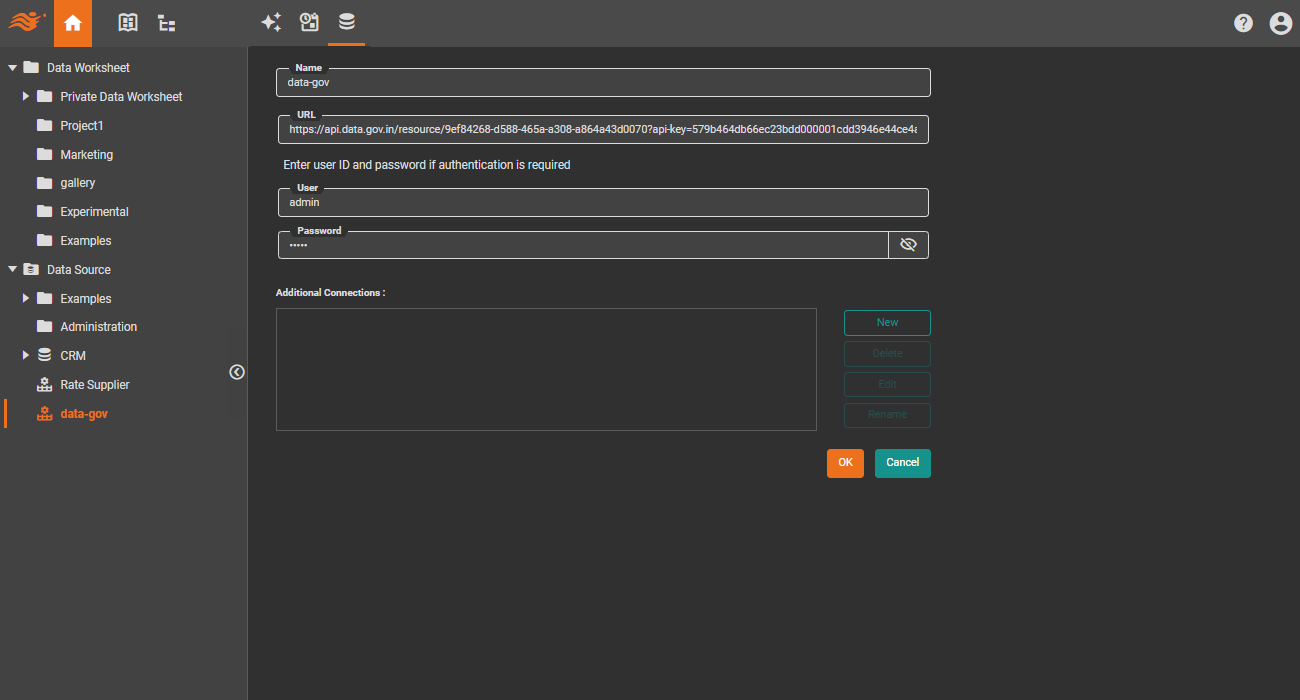


Transform and mash up
Anyone with a basic understanding of SQL can efficiently transform data.
Visual transformation
The embedded SQL engine enables data from any source to be visually manipulated using SQL semantics without SQL code.
Inline SQL and JavaScript
For advanced users, script snippets in SQL or JavaScript provide additional data control beyond visual manipulation.
System safety guardrails
Guardrails, such as preventing cross joins and limiting data volume, ensure that data operations do not jeopardize the safety of both StyleBI and the data source providers.
Intelligent optimization
The pipeline engine intelligently pushes data operations down to data sources for optimal performance while leveraging an embedded mashup engine for handling disparate data sources.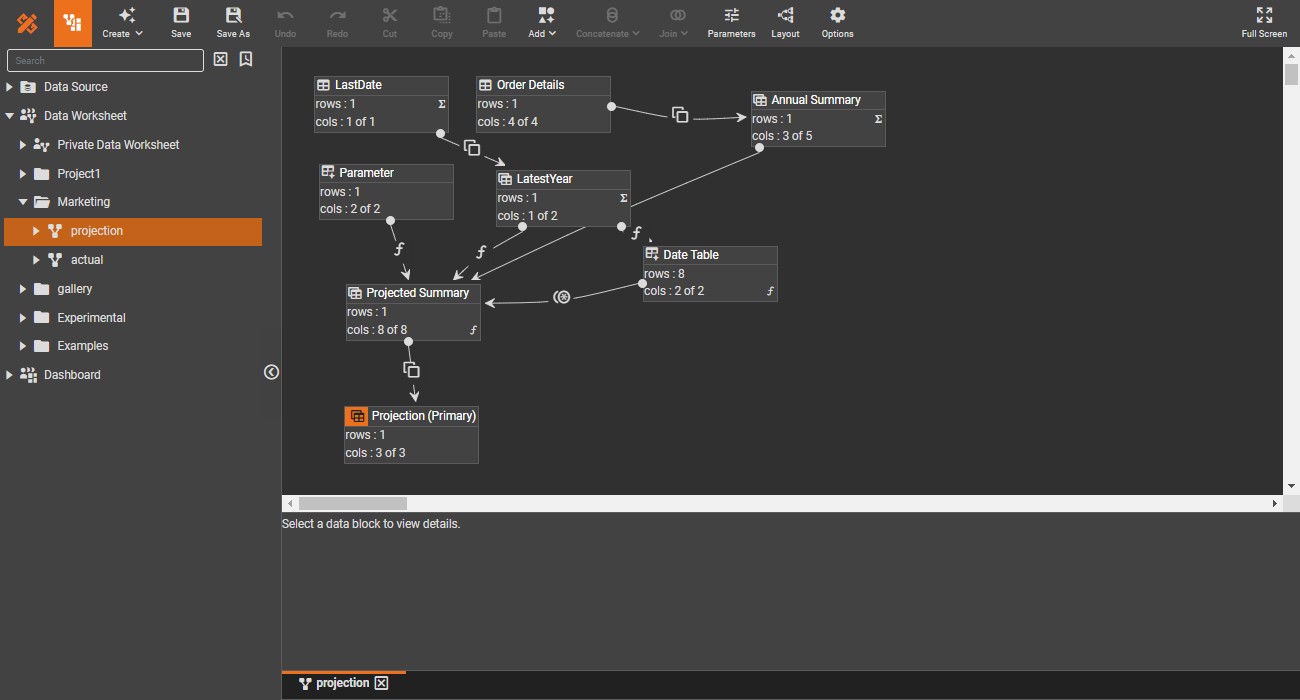

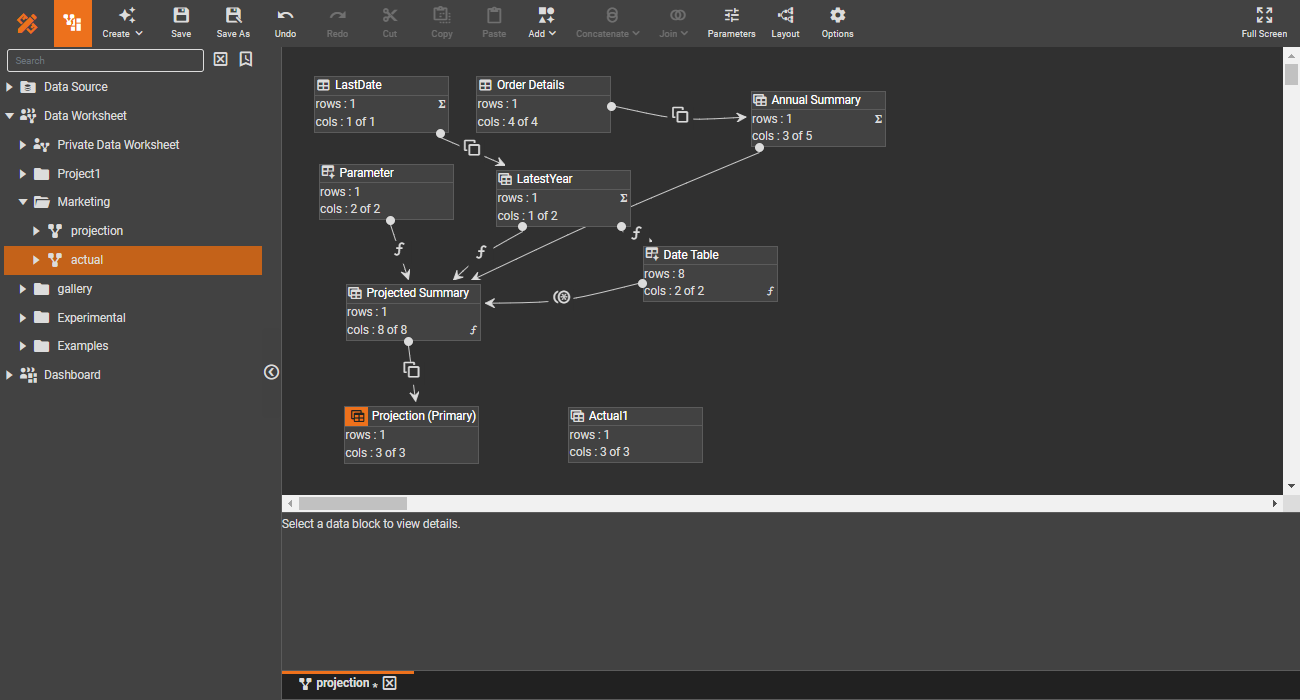

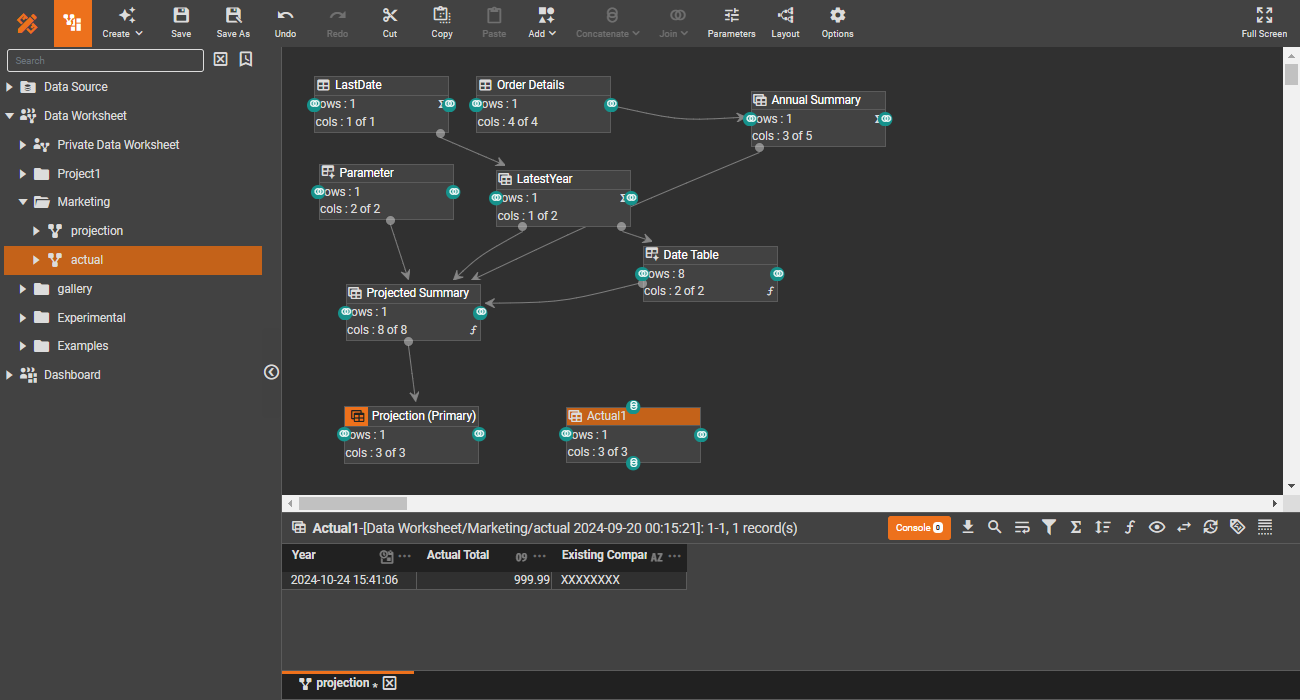
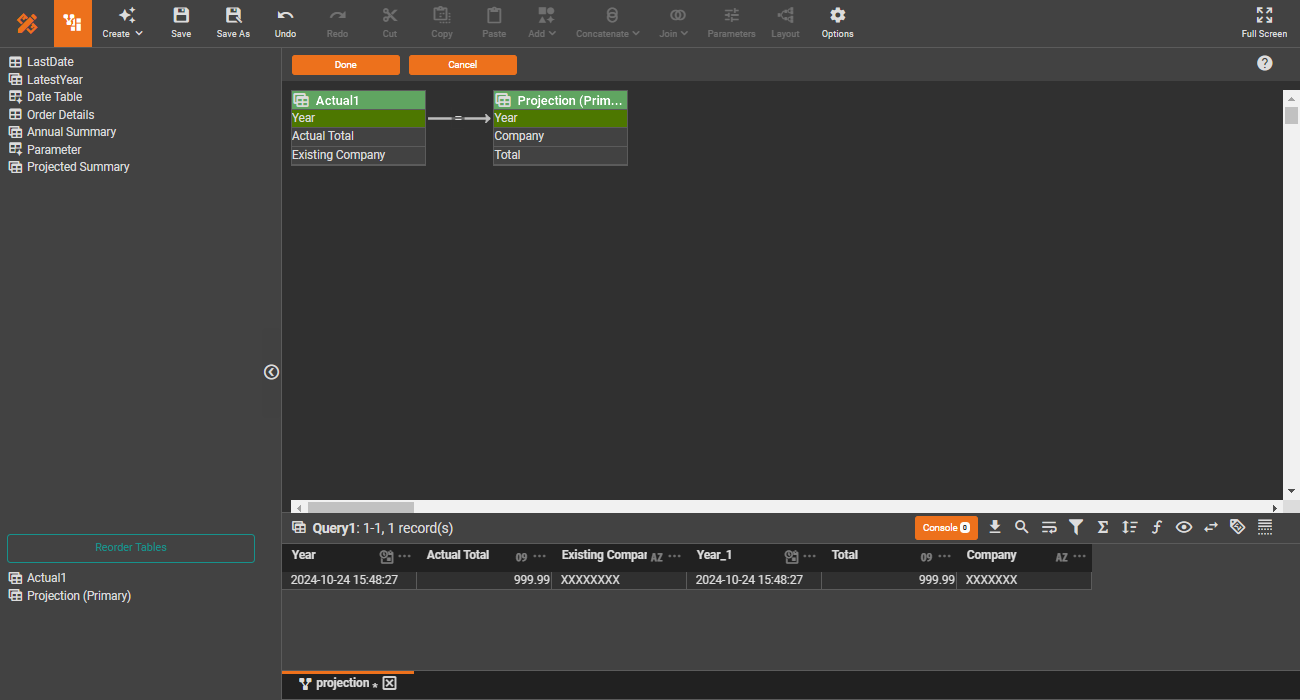
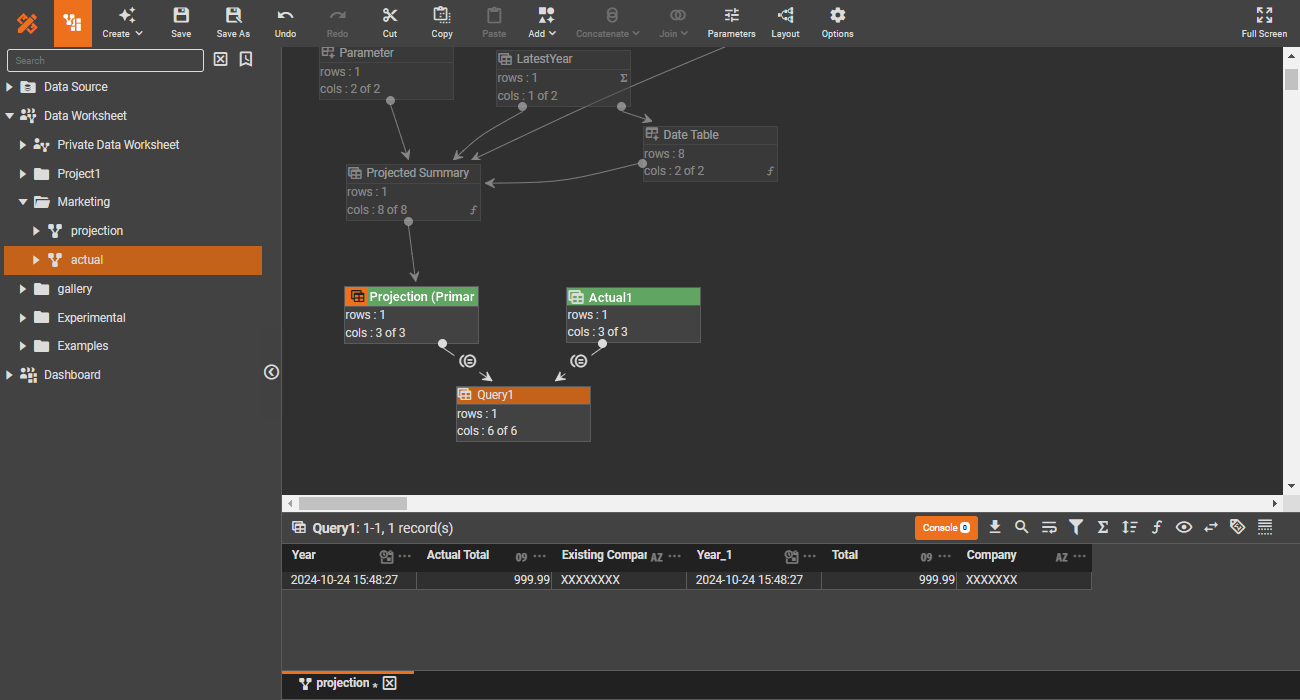

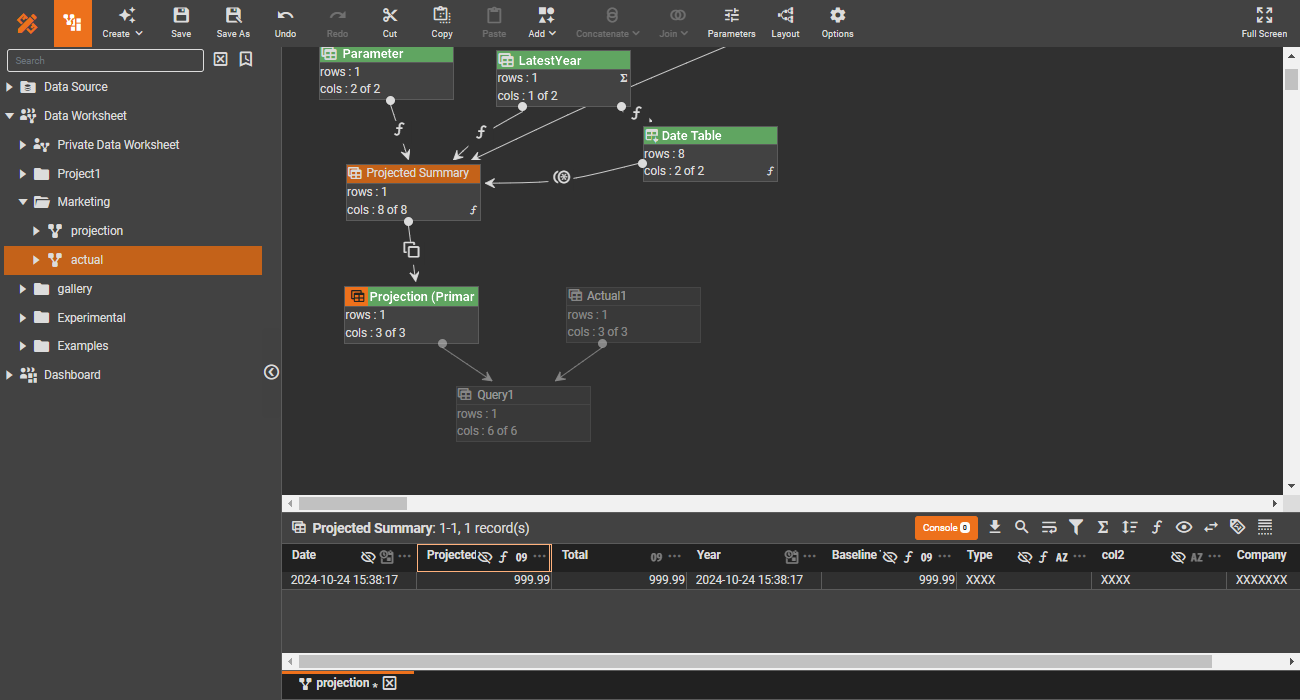
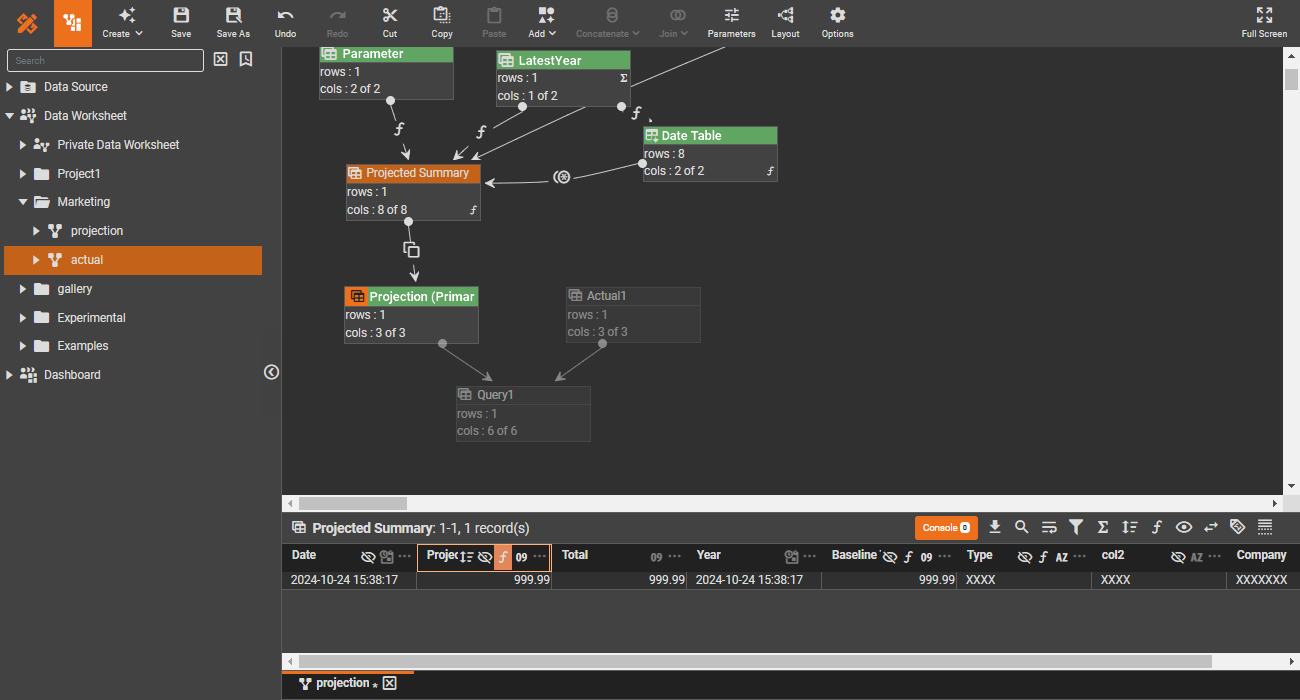
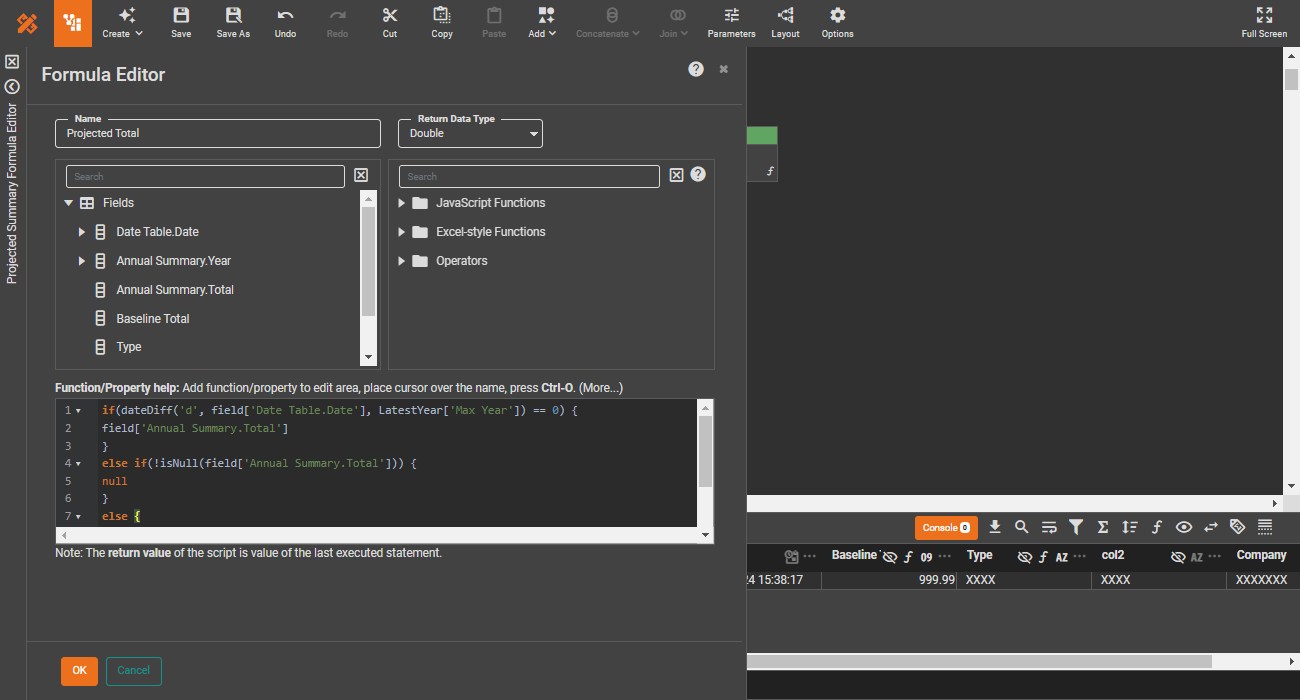
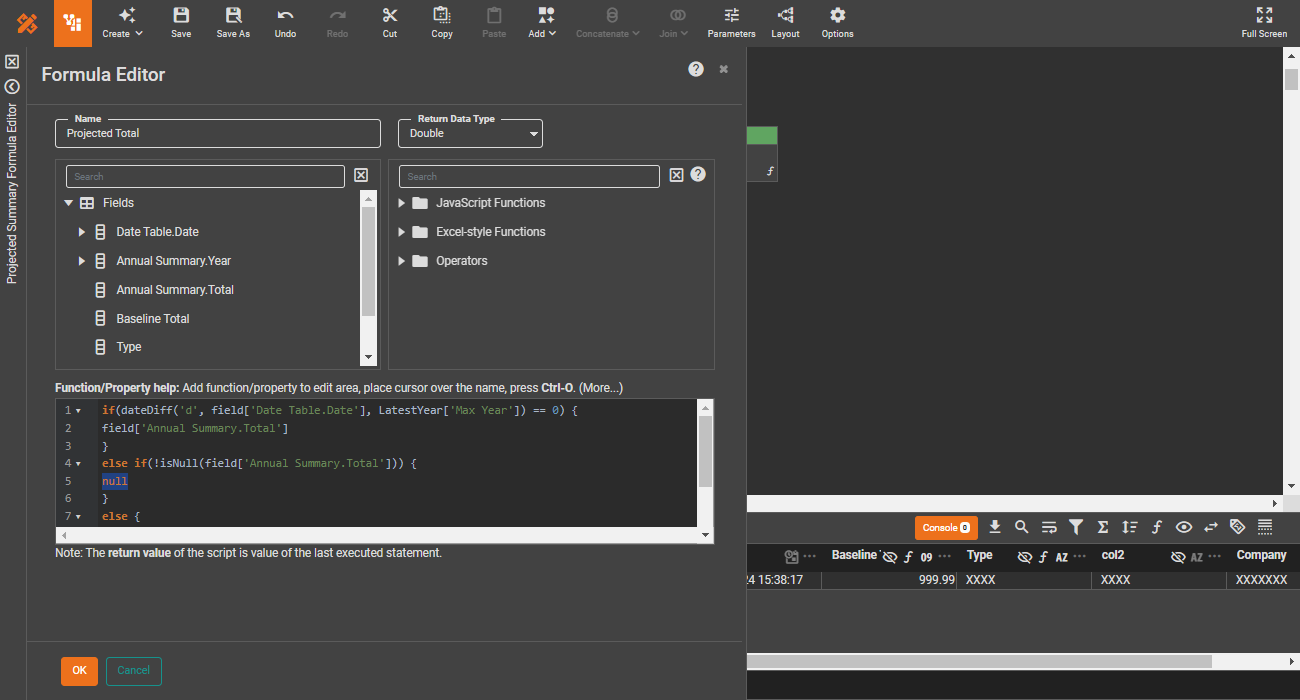
Data engineering
Apply software engineering best practices in data engineering.
Reusable modules
Reusability is a fundamental principle in software engineering. In data engineering, reusable core pipelines not only promote reusability but also provide a logical data view, abstracting away the technical complexities of the underlying physical data structure.

Data quality testing
Data quality is crucial. Drawing from software engineering practices, integrate test cases directly into your data pipeline. This way you can treat the test case results like any other data, enabling seamless visualization and monitoring of test outcomes alongside your actual data.


Automated monitoring
Test case monitoring can be automated using the alerting features of visualization tools. The scheduler runs alert visualizations and offers a variety of configuration options to customize how and when alerts are triggered and delivered.

